There are quite a few components to this blog now. There’s an AWS S3 bucket the blog gets served from, there’s a backend service responsible for the mouthful comments, there’s another instance of the service for the mouthful demo page, with another S3 bucket to serve the page for it. There’s also a yet unused service living in the same “cluster” as these two(It’ll get added to this blog soon™). There’s quite a few private github repositories that in unison with a Jenkins instance make this all work. Oh, and everything is running under Docker, with ECS handling all the orchestration for that. For the data stores, I use dynamodb, mysql and sqlite. There’s also some miscellaneous bits and bobs, like the grafana instance that plots response times and uptimes of the APIs. I’ve tried to keep as much as I can inside AWS but due to cost constraints I had to do some workarounds. So how does it all work then?
Firstly, a disclaimer. Since I’m not making money off this blog, I really really want it to be as cheap as it can. Therefore, what you’ll find below might scare the enterprise devops.
Jenkins
Initially, I had used a raspberry pi3 for the jenkins server. That was mostly due to having a spare rpi3 laying around and not having much to do with it. Also since I’m cheap, and AWS EC2 instances do cost a bit of money. I’ve since decided to upgrade, as the storage was struggling to keep up with the load I was putting it under. The blog is powered by hexo and that is node based meaning lots and lots of small files need to written to storage when an npm i is run. The SD card was the major bottleneck here. A build of the blog in a clean workspace would take at least half an hour. I’ve since upgraded to an old laptop I’ve got laying around. It’s a Dell XPS 15(probably a 2009 model). I’ve removed the old hard drive, and put in a 250GB SSD in it. The i5 and the 6GB of RAM in the laptop is enough to run jenkins quite comfortably. It’s running CentOS. It’s definitely the single point of failure in the whole infrastructure, so I’m making sure to back up every single job I have in a private github repo, making sure to encrypt it before a push happens and decrypt the sensitive files on a pull in the jenkins machine. I’m also looking for a way to back it up once in a while. That’s still in the works though and I’m looking at rsync and AWS glacier as a possibility here. If you’ve got a better solution, please let me know in the comments below. If the jenkins machine crashes - I’ll probably need somewhere around 5 hours to get it restored on a clean machine from what I have stored in the private repository. So what does this jenkins actually do? Well, it listens for repo changes for the blog, mouthful demo page, mouthful, a private nginx repo and the yet unannounced service. It then performs the build steps.
For the blog, that’s basicly baking the static pages and pushing them to S3 and invalidating a CloudFront distribution.
For mouthful, it builds both - the demo page backend service and the dizzy.zone commenting instance. It then builds a docker image, pushes it to AWS ECR and pushes updated task/service definitions to ECS.
For nginx, it build a new docker image for the nginx pushes it to ECR making sure to update the ECS task/service definitions as required.
ECS cluster
The ECS cluster I have is a whopping single T2.nano instance giving me a total of 512MB of RAM and 1 vCPU to play with. And in this cluster I have 4 services running. 2 of them are instances of mouthful: one for mouthful.dizzy.zone, the other for dizzy.zone. There’s also an nginx instance and a service that’s not yet in use. With this, I’m running at basically 10% memory usage and the CPU usage is non existent at all. That’s mostly due to writing everything with Go and having everything cached both in the instances and the CDN I use(more on that later).
Here’s a memory graph from the instance:

And the same for CPU:

The two mouthful instances are a bit different - the mouthful demo page one runs mouthful with no moderation and with sqlite as a data store(it’s not that important if we lose the comments here) and the other uses DynamoDB.
I was pretty surprised how much I can actually fit on a T2.nano. There’s plenty of space for a few services. One thing to note is that this blog is not all that popular so your mileage may vary.
To lower costs, I’m also running the T2.nano reserved instance.
nginx
The instance I’m running only exposes port 80. So for internal routing to the various services I use nginx. It basicly reroutes certain paths to certain services(running docker containers), as well as adding some headers to the resources that need to be cached or adding a no-cache header to those that don’t.
CDN
For CDN I use CloudFront. It allows for easy SSL setup, forcing http -> https redirects and caching of relevant resources. All of the distributions are spread through all of the edge locations amazon provides for maximum speed.
I’ve got quite a few CloudFront distributions set up:
- One for dizzy.zone
- One for mouthful.dizzy.zone
- One for api.dizzy.zone -> this points to the EC2 T2.nano
- A few more static websites are hosted on S3, so we point to those.
- Where applicable, I also include the www subdomain distributions.
DynamoDB
The DynamoDB is a godsend. Its free tier(one that does not expire at the end of 12 months) is absolutely amazing. With all the other options on AWS being rather expensive in terms of databases it’s been a rather easy choice for me and I’ve been happy with it. The mouthful instance for the blog never even approaches the limit I’ve set on the tables. I’m pretty sure you can create a decent production-ready application on it with the free tier. Do take this with a grain of salt though as I’m not expert on the matter. Nonetheless I’m confident there’s room for optimizations to be done in my implementation of it and I have a complete rewrite of the mouthful DynamoDB layer in my mind, just haven’t gotten to it yet. It was the first real attempt at using DynamoDB and I’m not completely impressed at the job I’ve done.
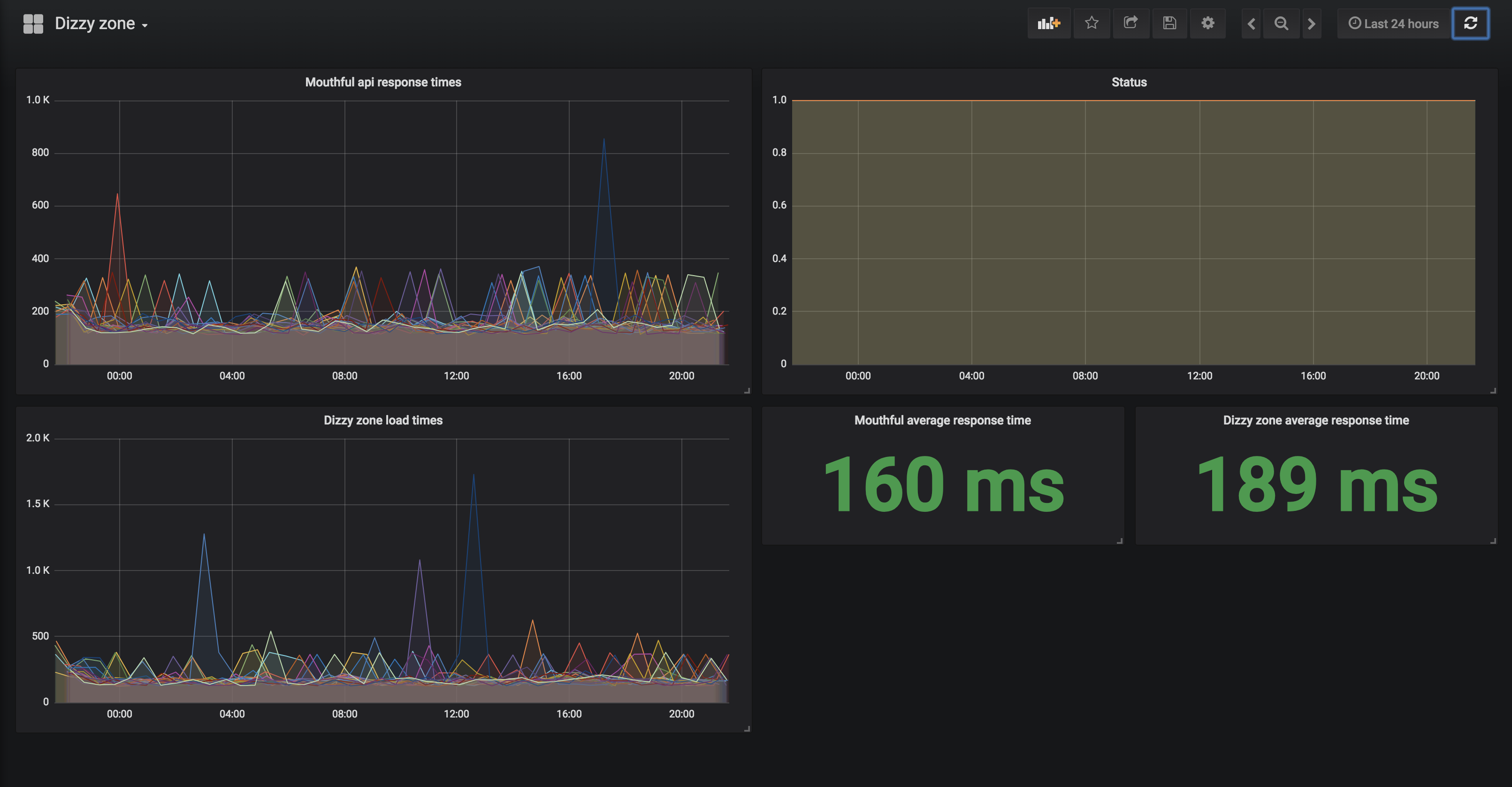
Grafana
For monitoring purposes, I use grafana to plot the average response times of the apis and the website itself as well as having a graph showing if the apis/website are available. The data comes from a mysql instance running on the same host. The host also contains a service I’ve hacked in Go in a couple of hours. The service allows for registering of targets(URL’s) to hit with specified frequency. It then logs the response code and the time it took to respond and adds it to the mysql instance. Due to terrible code it’s not public yet, but maybe someday. Oh and the host I’m referring to is the same old laptop I’m running my jenkins on.
This setup is mostly used to detect trends that might occur, such as slowdown of services once the amount of comments grows, or once the T2.nano instance starts to struggle with the load. I’m hoping my laser eyeball will be able to spot the issues before they become critical.
Here’s a snap of the dashboard I’ve set up:
The costs
So how much does it all cost? I’ll do a run down without the VAT here.
Well, not much really. A usual month for me costs me less than 12$. However, that is not representative of the writeup above, as I have quite a few other projects hosted there. Making adjustments for that, I’ll assume that it costs me around 8$ to keep what I’ve written above running.
Here’s the bill:
- EC2 instance - 3.27$
- EBS - the volume attached to the EC2 - 3.30$
- ECR - 0.05$
- Route53 - 1.51$
- CloudFront - 0.33$
- DynamoDB - free
- DynamoDB backup storage - 0.01$
- S3 - 0.03$
- Misc - 0.03$
For a grand total of 8.53$ before tax.
There’s also the hidden electricity cost of running an old laptop. I have no clue how much power it consumes, so I’ve left it out of the calculations.
In terms of these costs growing, I do not see any issues with the current infrastructure unless I see more than 50fold increase in blog readers. There will be minor costs penalties to that, but I’m pretty sure those will be limited to Route53 and CloudFront.
If I weren’t on a budget
There’s a few things I’d change if I weren’t on the budget. First, I’d get rid of the nginx and put an application load balancer there instead. Then I’d change the caching on mouthful to a full fledged redis instance(I just like redis). Afterwards, I’d spin up a few more T2.nano instances and replicate the setup on each of them. This way I’d be able to scale quite well. I think - at least. Hopefully, time will tell.
And this concludes the overview of the infrastructure I’ve got around the blog. Hope you enjoyed!
So what do you guys think of my infrastructure? Anything I could improve? Maybe I’ve got something completely wrong and deserve to go to the OPS hell? Do let me know in the comments.