SQLC has become my go-to tool for interacting with databases in Go. It gives you full control over your queries since you end up writing SQL yourself. It then generates models and type safe code to interact with those queries.
I won’t go over the basics here, if you feel like it you can try their interactive playground.
Dynamic queries
Frequently I end up needing to filter the data by a set of fields in the database. This set of fields is often determined by the caller, be it via REST API or other means. This means that the code I’m writing has to support dynamic queries, where we query by a subset of fields.
Let’s see an example. Assume my API returns some car data and I store it in the following table:
CREATE TABLE cars(
id SERIAL PRIMARY KEY,
brand VARCHAR(255) NOT NULL,
model VARCHAR(255) NOT NULL,
year INT NOT NULL,
state VARCHAR(255) NOT NULL,
color VARCHAR(255) NOT NULL,
fuel_type VARCHAR(50) NOT NULL,
body_type VARCHAR(50) NOT NULL
);The user might want to filter by brand, or by model. Or by brand and model. Or by brand, color, model, state and body type. You get the point, there’s a whole bunch of permutations here and SQLC is not great at handling this.
I usually approach it with the following SQLC query:
SELECT * FROM cars
WHERE brand = @brand -- mandatory fields go in like this
AND (NOT @has_model::boolean or model = @model) -- optional fields follow this pattern
AND (NOT @has_year::boolean or year = @year)
AND (NOT @has_state::boolean or state = @state)
AND (NOT @has_color::boolean or color = @color)
AND (NOT @has_fuel_type::boolean or fuel_type = @fuel_type)
AND (NOT @has_body_type::boolean or body_type = @body_type);It might not be the prettiest solution, but it has worked for me quite well. There are a couple of downsides though. First, the param struct that the SQLC generates contains quite a bunch of fields:
type GetCarsParams struct {
Brand string
HasModel bool
Model string
HasYear bool
Year int32
HasState bool
State string
HasColor bool
Color string
HasFuelType bool
FuelType string
HasBodyType bool
BodyType string
}You’ll have to handle this in your code, to set the proper ones if the user provides the relevant input. Second, people always ask me if there is a cost associated with having such a query versus using something like a query builder to build the query with specific params. To this, I always answer: “Probably, but it’s unlikely you’ll notice”.
I have decided to try and benchmark this, to see if there is a meaningful cost associated with it.
Benchmarking setup
I’ll use postgres & pgbench, since I’m only really interested in the query performance ignoring any code overhead. For schema, we’ll use the table above.
We’ll seed the data with the following query:
INSERT INTO cars(brand, model, YEAR, state, color, fuel_type, body_type)
SELECT (CASE FLOOR(RANDOM() * 5)::INT
WHEN 0 THEN 'Toyota'
WHEN 1 THEN 'Ford'
WHEN 2 THEN 'Honda'
WHEN 3 THEN 'BMW'
WHEN 4 THEN 'Tesla'
END) AS brand,
(CASE FLOOR(RANDOM() * 5)::INT
WHEN 0 THEN 'Camry'
WHEN 1 THEN 'F-150'
WHEN 2 THEN 'Civic'
WHEN 3 THEN '3 Series'
WHEN 4 THEN 'Model S'
END) AS model,
(CASE FLOOR(RANDOM() * 5)::INT
WHEN 0 THEN 2024
WHEN 1 THEN 2023
WHEN 2 THEN 2022
WHEN 3 THEN 2021
WHEN 4 THEN 2020
END) AS YEAR,
(CASE FLOOR(RANDOM() * 3)::INT
WHEN 0 THEN 'Operational'
WHEN 1 THEN 'Under maintenance'
WHEN 2 THEN 'Totalled'
END) AS state,
(CASE FLOOR(RANDOM() * 5)::INT
WHEN 0 THEN 'Red'
WHEN 1 THEN 'Green'
WHEN 2 THEN 'Blue'
WHEN 3 THEN 'Black'
WHEN 4 THEN 'White'
END) AS color,
(CASE FLOOR(RANDOM() * 3)::INT
WHEN 0 THEN 'Diesel'
WHEN 1 THEN 'Petrol'
WHEN 2 THEN 'Electric'
END) AS fuel_type,
(CASE FLOOR(RANDOM() * 3)::INT
WHEN 0 THEN 'Sedan'
WHEN 1 THEN 'SUV'
WHEN 2 THEN 'Hatchback'
END) AS body_type
FROM GENERATE_SERIES(1, 10000000) seq;We’ll then have two different queries - one that we’d build with a query builder:
SELECT * FROM cars
WHERE brand = 'Ford'
and model = 'Model S'
and year = 2021
and color = 'Green'
and fuel_type = 'Diesel';And one where we’d have some extra overhead from our SQLC approach:
SELECT * FROM cars
WHERE brand = 'Ford'
AND (NOT true::boolean or model = 'Model S')
AND (NOT true::boolean or year = 2021)
AND (NOT false::boolean or state = '')
AND (NOT true::boolean or color = 'Green')
AND (NOT true::boolean or fuel_type = 'Diesel')
AND (NOT false::boolean or body_type = '');I’ve also added a composite index for these specific queries:
CREATE INDEX idx_cars_brand_model_year_color_fuel
ON cars (brand, model, year, color, fuel_type);Armed with this, I’ve spun up an instance of postgres in docker on my machine, created the schema and generated the dataset. I then pre-warmed the cache by executing a couple of pgbench runs but not logging any results.
From there, I ran pgbench 4 times:
pgbench -f builderq.sql --log --log-prefix=builder --transactions=10000 -j 5 -c 5
pgbench -f sqlcq.sql --log --log-prefix=sqlc --transactions=10000 -j 5 -c 5
pgbench -f builderq.sql --log --log-prefix=builder --transactions=1000 -j 5 -c 5
pgbench -f sqlcq.sql --log --log-prefix=sqlc --transactions=10000 -j 5 -c 5
And these are the latencies for both queries after being run through plotly:
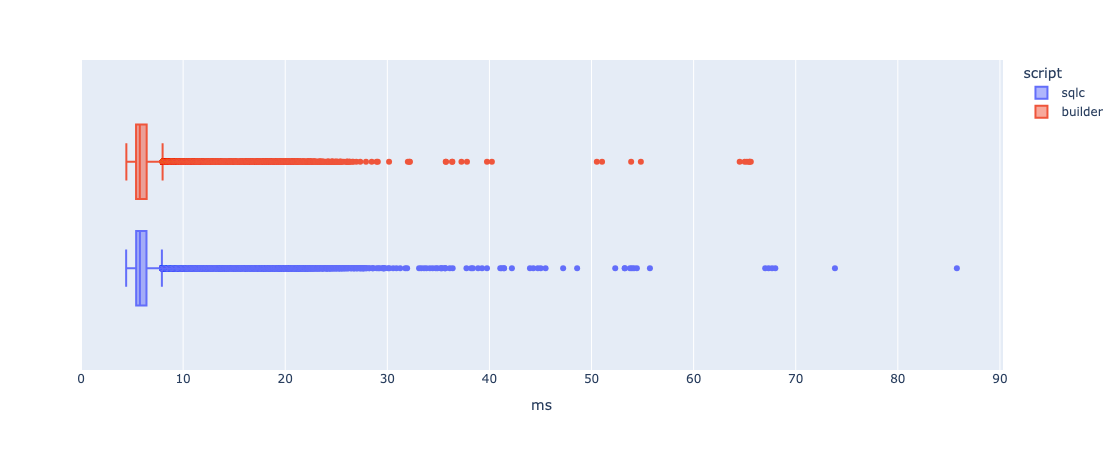
There is very little difference between the two, with SQLC approach having a larger number of outliers. Despite this, I would state that there is no significant difference between the two.
I then re-ran the experiment, only this time introduced a limit of 1 on both queries. My thought process was that this would perhaps allow the faster(in theory) query to shine, since we would not have to spend so much time transferring data. Here is the box plot:
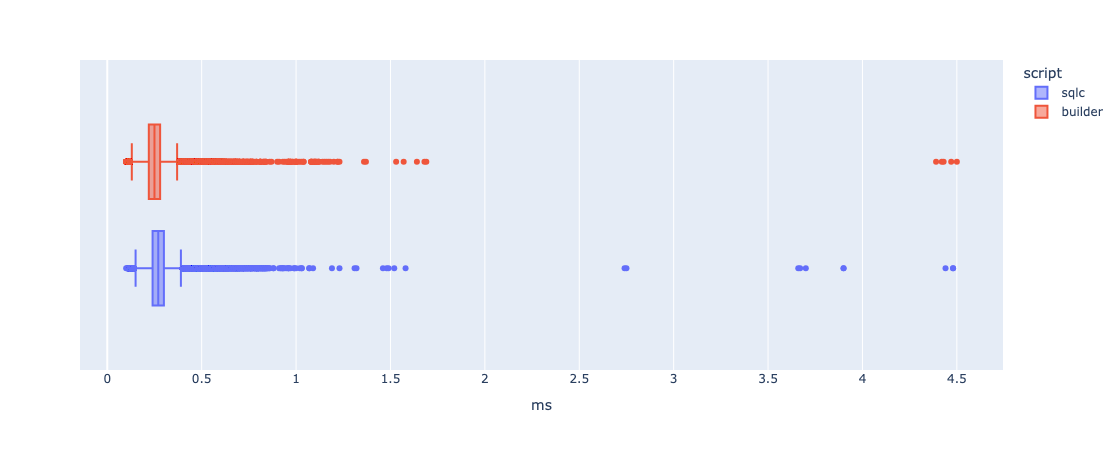
The SQLC approach does seem a tad slower here, but not by a lot.
In conclusion, there is very little difference in terms of performance for these queries, meaning that using the a bunch of ANDs to implement dynamic querying in SQLC is something you can do without fear of massive performance repercussions. Your mileage may vary and in extreme cases this might not be these - always benchmark your own use cases.
The only price you pay for manually constructing the dynamic queries is the manual work involved in writing the queries & mapping of values from the request parameters to the query parameters.
Thanks for reading! If you’ve enjoyed my babbling you might also like my post on SQL string constant gotcha.