About cache stampedes
I often end up in situations where I need to cache this or that. Often, these values are cached for a period of time. You’re probably familiar with the pattern. You try to get a value from cache, if you succeed, you return it to the caller and call it a day. If the value is not there, you fetch it(most likely from the database) or compute it and the put it in the cache. In most cases, this works great. However, if the key you’re using for your cache entry gets accessed frequently and the operation to compute the data takes a while you’ll end up in a situation where multiple parallel requests will simultaneously get a cache miss. All of these requests will independently load the from source and store the value in cache. This results in wasted resources and can even lead to a denial of service.
Let me illustrate with an example. I’ll use redis for cache and a simple Go http server on top. Here’s the full code:
package main
import (
"errors"
"log"
"net/http"
"time"
"github.com/redis/go-redis/v9"
)
type handler struct {
rdb *redis.Client
cacheTTL time.Duration
}
func (ch *handler) simple(w http.ResponseWriter, r *http.Request) {
cacheKey := "my_cache_key"
// we'll use 200 to signify a cache hit & 201 to signify a miss
responseCode := http.StatusOK
cachedData, err := ch.rdb.Get(r.Context(), cacheKey).Result()
if err != nil {
if !errors.Is(err, redis.Nil) {
log.Println("could not reach redis", err.Error())
http.Error(w, "could not reach redis", http.StatusInternalServerError)
return
}
// cache miss - fetch & store
res := longRunningOperation()
responseCode = http.StatusCreated
err = ch.rdb.Set(r.Context(), cacheKey, res, ch.cacheTTL).Err()
if err != nil {
log.Println("failed to set cache value", err.Error())
http.Error(w, "failed to set cache value", http.StatusInternalServerError)
return
}
cachedData = res
}
w.WriteHeader(responseCode)
_, _ = w.Write([]byte(cachedData))
}
func longRunningOperation() string {
time.Sleep(time.Millisecond * 500)
return "hello"
}
func main() {
ttl := time.Second * 3
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
handler := &handler{
rdb: rdb,
cacheTTL: ttl,
}
http.HandleFunc("/simple", handler.simple)
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatalf("Could not start server: %s\n", err.Error())
}
}Let’s put some load on the /simple endpoint and see what happens. I’ll use vegeta for this.
I run vegeta attack -duration=30s -rate=500 -targets=./targets_simple.txt > res_simple.bin. Vegeta ends up making 500 requests every second for 30 seconds. I graph them as a histogram of HTTP result codes with buckets that span 100ms each. The result is the following graph.
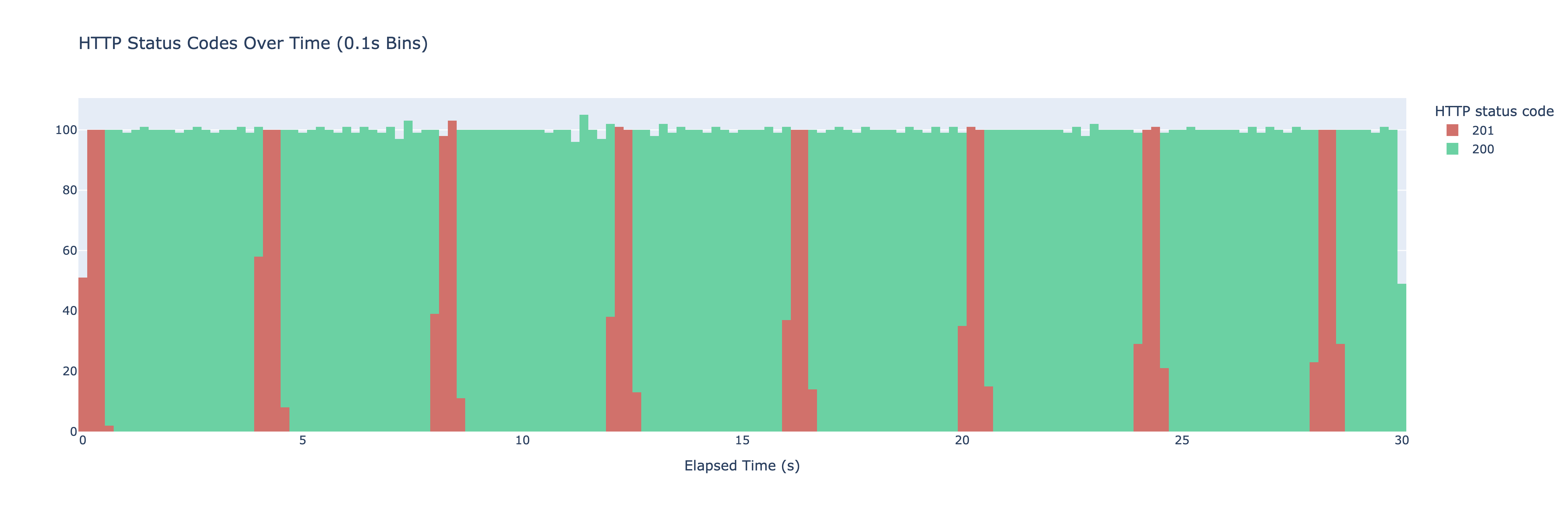
When we start the experiment the cache is empty - we have no value stored there. We get the initial stampede as a bunch of requests reach our server. All of them check the cache find nothing there, call the longRunningOperation and store it in cache. Since the longRunningOperation takes ~500ms to complete any requests made in the first 500ms end up calling longRunningOperation. Once one of the requests manages to store the value in the cache all the following requests fetch it from cache and we start seeing responses with the status code of 200. The pattern then repeats every 3 seconds as the expiry mechanism on redis kicks in.
In this toy example this doesn’t cause any issues but in a production environment this can lead to unnecessary load on your systems, degraded user experience or even a self induced denial of service. So how can we prevent this? Well, there’s a few ways. We could introduce a lock - any cache miss would result in code trying to achieve a lock. Distributed locking is not a trivial thing to do and often these have subtle edge cases that require delicate handling. We could also periodically re-compute the value using a background job but this requires an extra process to be running introducing yet another cog that needs to be maintained and monitored in our code. This approach might also not be feasible to do if you have dynamic cache keys. There is another approach, called probabilistic early expiration and this is something I’d like to explore further.
Probabilistic early expiration
This technique allows one to recompute the value based on a probability. When fetching the value from cache, you also compute if you need to regenerate the cache value based on a probability. The closer you are to the expiry of the existing value, the higher the probability.
I’m basing the specific implementation on XFetch by A. Vattani, F.Chierichetti & K. Lowenstein in Optimal Probabilistic Cache Stampede Prevention.
I’ll introduce a new endpoint on the HTTP server which will also perform the expensive calculation but this time use XFetch when caching. For XFetch to work, we need to store how long the expensive operation took(the delta) and when the cache key expires. To achieve that, I’ll introduce a struct that will hold these values as well as the message itself:
type probabilisticValue struct {
Message string
Expiry time.Time
Delta time.Duration
}I add a function to wrap the original message with these attributes & serialize it for storing in redis:
func wrapMessage(message string, delta, cacheTTL time.Duration) (string, error) {
bts, err := json.Marshal(probabilisticValue{
Message: message,
Delta: delta,
Expiry: time.Now().Add(cacheTTL),
})
if err != nil {
return "", fmt.Errorf("could not marshal message: %w", err)
}
return string(bts), nil
}Let’s also write a method to recompute and store the value in redis:
func (ch *handler) recomputeValue(ctx context.Context, cacheKey string) (string, error) {
start := time.Now()
message := longRunningOperation()
delta := time.Since(start)
wrapped, err := wrapMessage(message, delta, ch.cacheTTL)
if err != nil {
return "", fmt.Errorf("could not wrap message: %w", err)
}
err = ch.rdb.Set(ctx, cacheKey, wrapped, ch.cacheTTL).Err()
if err != nil {
return "", fmt.Errorf("could not save value: %w", err)
}
return message, nil
}To determine if we need to update the value based on the probability, we can add a method to probabilisticValue:
func (pv probabilisticValue) shouldUpdate() bool {
// suggested default param in XFetch implementation
// if increased - results in earlier expirations
beta := 1.0
now := time.Now()
scaledGap := pv.Delta.Seconds() * beta * math.Log(rand.Float64())
return now.Sub(pv.Expiry).Seconds() >= scaledGap
}If we hook it all up we end up with the following handler:
func (ch *handler) probabilistic(w http.ResponseWriter, r *http.Request) {
cacheKey := "probabilistic_cache_key"
// we'll use 200 to signify a cache hit & 201 to signify a miss
responseCode := http.StatusOK
cachedData, err := ch.rdb.Get(r.Context(), cacheKey).Result()
if err != nil {
if !errors.Is(err, redis.Nil) {
log.Println("could not reach redis", err.Error())
http.Error(w, "could not reach redis", http.StatusInternalServerError)
return
}
res, err := ch.recomputeValue(r.Context(), cacheKey)
if err != nil {
log.Println("could not recompute value", err.Error())
http.Error(w, "could not recompute value", http.StatusInternalServerError)
return
}
responseCode = http.StatusCreated
cachedData = res
w.WriteHeader(responseCode)
_, _ = w.Write([]byte(cachedData))
return
}
pv := probabilisticValue{}
err = json.Unmarshal([]byte(cachedData), &pv)
if err != nil {
log.Println("could not unmarshal probabilistic value", err.Error())
http.Error(w, "could not unmarshal probabilistic value", http.StatusInternalServerError)
return
}
if pv.shouldUpdate() {
_, err := ch.recomputeValue(r.Context(), cacheKey)
if err != nil {
log.Println("could not recompute value", err.Error())
http.Error(w, "could not recompute value", http.StatusInternalServerError)
return
}
responseCode = http.StatusAccepted
}
w.WriteHeader(responseCode)
_, _ = w.Write([]byte(cachedData))
}The handler works much like the first one, however, upon getting a cache hit we roll the dice. Depending on the outcome we either just return the value we just fetched, or update the value early.
We’ll use the HTTP status codes to determine between the 3 cases:
- 200 - we returned the value from cache
- 201 - cache miss, no value present
- 202 - cache hit, triggered probabilistic update
I start up vegeta once again this time running against the new endpoint and here’s the result:
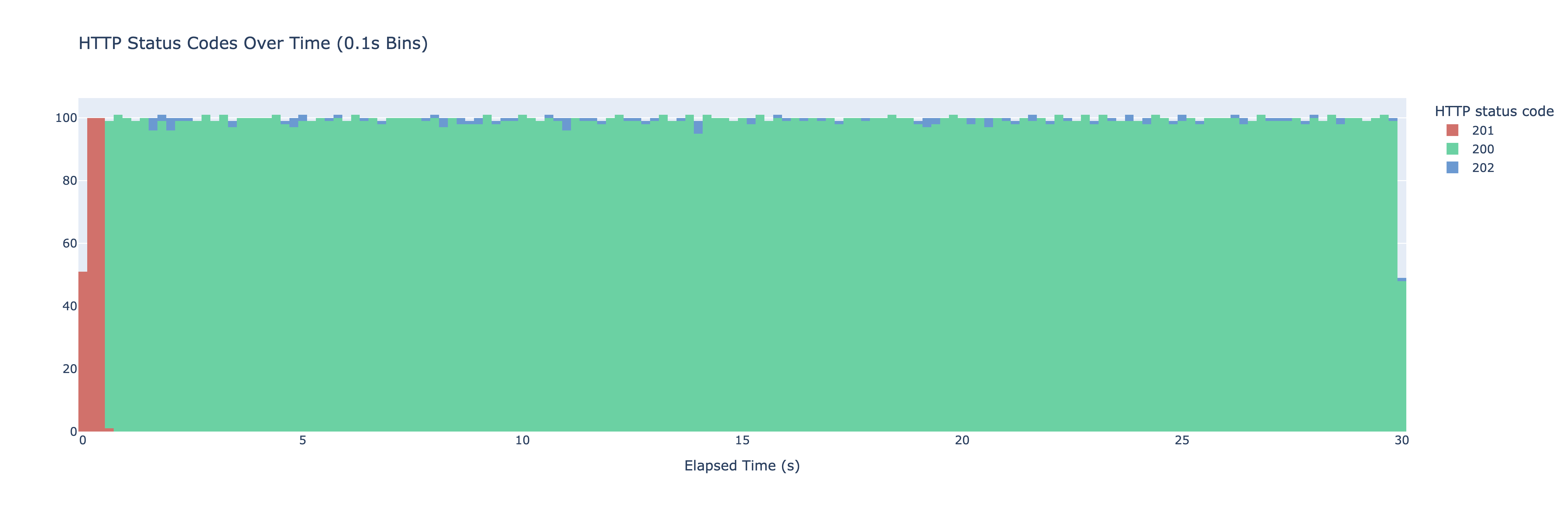
The tiny blue blobs there indicate when we actually ended up updating the cache value early. We no longer see cache misses after the initial warm up period. To avoid the initial spike you could pre-store the cached value if this is important for your use case.
If you’d like to be more aggressive with your caching and refresh the value more frequently, you can play with the beta parameter. Here’s what the same experiment looks like with the beta param set to 2:
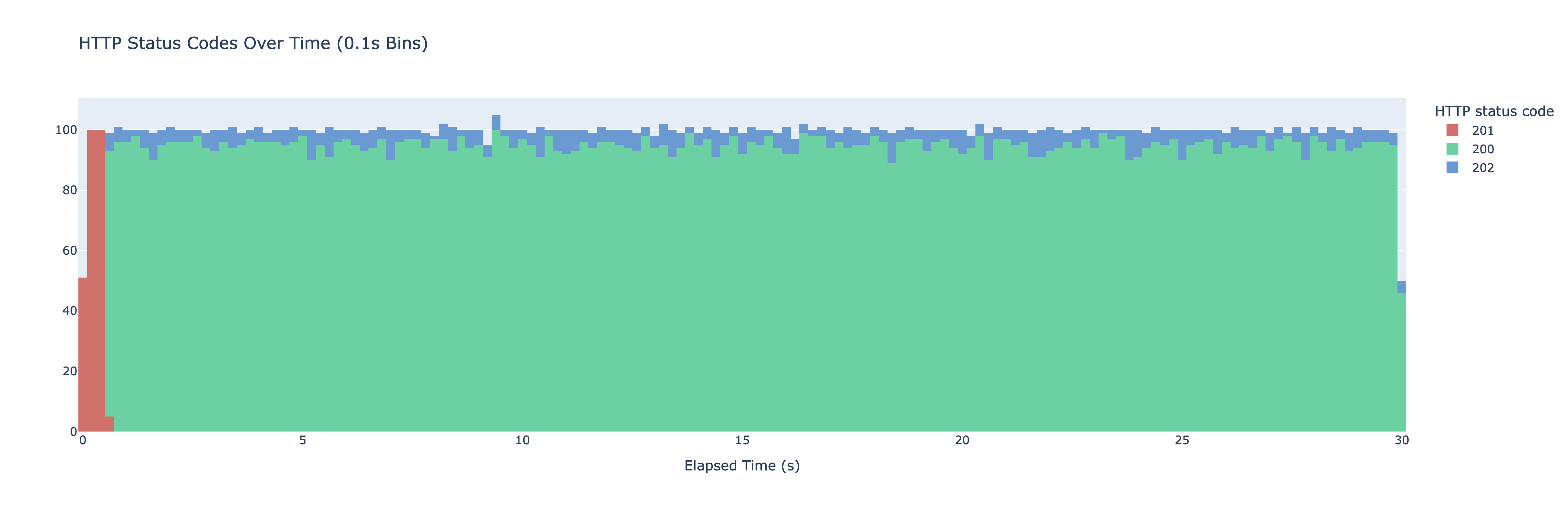
We’re now seeing probabilistic updates way more frequently.
All in all this is a neat little technique that can help with avoiding cache stampedes. Keep in mind though, this only works if you are periodically fetching the same key from the cache - otherwise you won’t see much benefit.
Got another way of dealing with cache stampedes? Noticed a mistake? Let me know in the comments below!