After reading the technicalwriting.dev post on embeddings I thought to myself - this seems like something that I can implement quite quickly and would serve as a good starting point for some hands on experience with machine learning. I want to start small, so something as simple as filling the related posts section of this blog seems like an ideal candidate to get my hands dirty.
This blog is made with Hugo and uses the related content feature which provides a list of related posts based on the tags & keywords you use. While I have no quarrels with the mechanism, I thought this would be a good place to try and experiment with embeddings.
The thought process
Since this blog is static, and I’d like it to keep it that way wherever possible I figured I’ll need to pre-compute the related posts for each post whenever a Hugo build is issued. However, there seems to be no way to natively hook into the Hugo’s build pipeline, so I’ll have to handle this via a script. The script would build a matrix of posts and their embeddings, compare each post to the rest of the posts and rank them according to their cosine similarity. I’d then keep the top N of those. I would then need to get Hugo to render these as links to those posts. To achieve this, I’ll have to save the recommended posts as part of the original post, probably in the frontmatter, so that these are available when rendering the related posts section via Hugo.
This pretty much lead me to the following architecture:
- A CLI(written in Go) to compare posts via their embeddings and manipulate the
.mdfiles. - An API(written in Python) with a model to calculate an embedding for a given text.
I could write everything in Python and have a single CLI for this, but my intent is to have this as a part of a generic blog cli helper tool which I’d like to keep in Go. Ideally, I’d stick with Go for the API part as well but using Python here makes life easier due to the excellent ML support and plentiful examples. I might re-visit this choice at some point though.
Keep in mind that any code you find here is just a script intended for personal use, it will not be the prettiest or most optimized code you’ve ever seen, but that’s not my goal here.
Choosing the model
ML models can be huge. I’m not aiming for a world-class solution here, and I’d like something that is reasonably small as I intend to run it on my homelab. My homelab runs on very modest hardware - second hand 1L computers with no dedicated GPUs, old CPUs and limited amounts of RAM, so I’d like something relatively small. Since I’m going to feed in full blog posts, I might choose something with a larger token limit. Other than that, I have very limited knowledge of what I should pay attention to as far as models for this specific task.
After typing in a few search queries, I’ve stumbled upon the Massive Text Embedding Benchmark (MTEB) Leaderboard. I then glanced through the list, choosing jina-embeddings-v3 due to its small size(2.13GB listed memory usage) and good accuracy - that’s the hope, at least - it’s rank 26 on the leaderboard at the time of writing after all.
The API
From there, I’ve opted to quickly build a super small python HTTP API with a single endpoint. It takes a POST at /embedding with a payload of:
{
"text": "Lorem ipsum dolor sit amet."
}And returns an embedding:
[
0.052685488015413284,
// omitted 1022 entries for brevity
// ...
0.017726296558976173
]I tested this locally and found that the embedding calculation can take some time. For longer texts, this might take as long as 10 seconds. While I don’t expect to run the process for all the posts in my blog frequently, I figured I’d need to add some persistence here. I intend to run this on my homelab, which consists of 1L post lease machines with no dedicated GPUs and old generations of CPUs so it would be even slower there. To keep things simple, I opted to add support for a postgres table that stores the hash of the input text as well as the resulting embedding. Upon receiving a request I’ll calculate the hash of the text and check for its existence in the database first allowing for quick responses if a text has already been processed. In reality this means that unless I edit a blog post, an embedding response for it should be rapid if I had it calculated in the past.
I also added an optional API token to add some very crude auth support.
I then wrote a Dockerfile for it, and proceeded to host it in my homelab. With it now accessible by my CLI, I had the API ready.
Oh, and it’s currently using right around ~3.6GiB of memory:
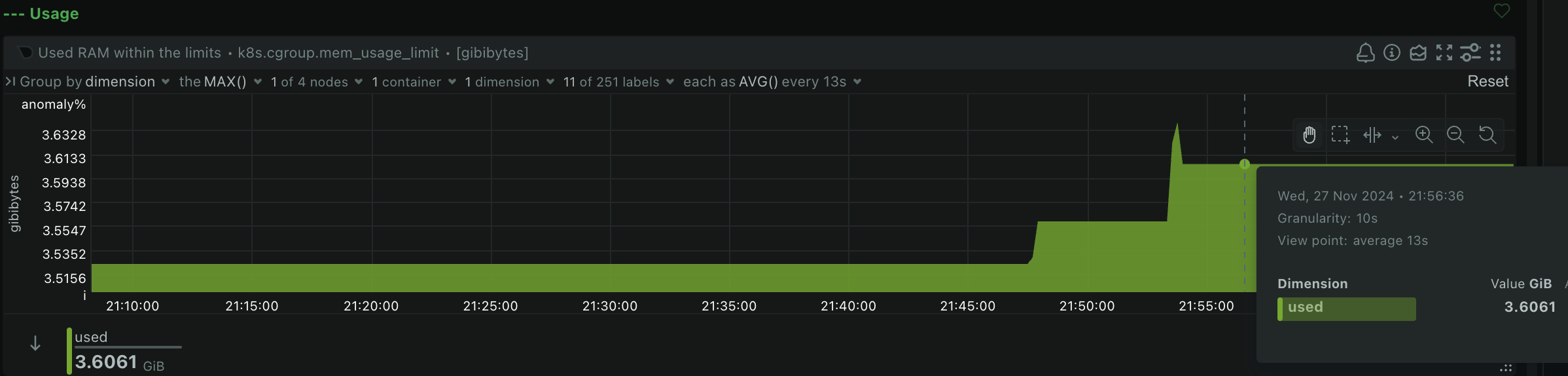
To calculate embeddings for a single blog post usually takes around 7 seconds on my hardware. The time scales with the length of the post. It also seems to consume a full CPU core when doing so:
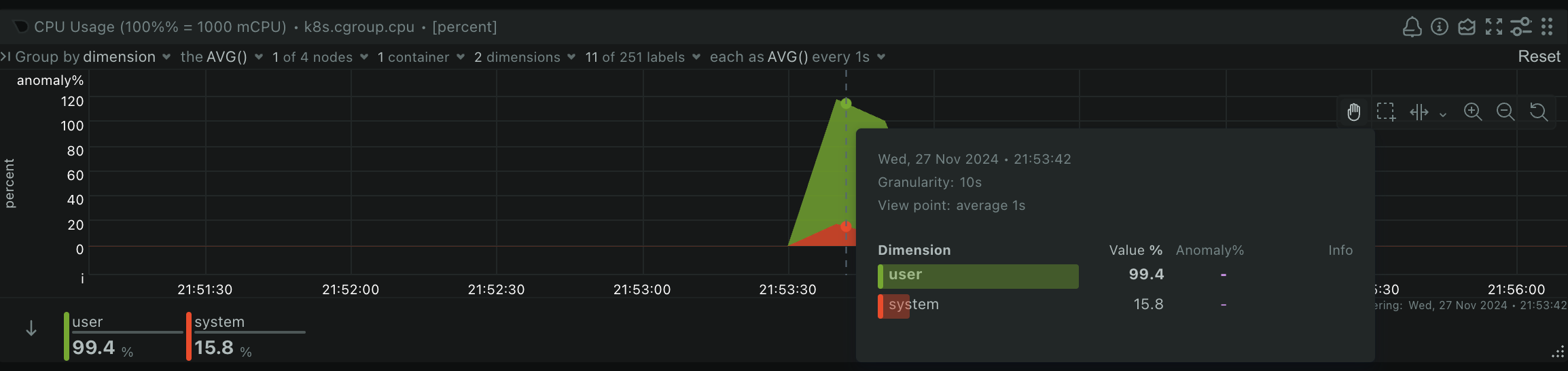
The full code for the API is available here.
The CLI
The folder structure of my blog posts looks something like this:
content/
├── posts/
│ ├── 2024/
│ │ ├── post-title/
│ │ | └── index.md
The cli accepts a base path, ./content/ in my case. It will walk through the directory, parsing each index.md file as a post. It will store it in memory, in the following structure:
type Frontmatter struct {
Title string `yaml:"title"`
Date time.Time `yaml:"date"`
Draft bool `yaml:"draft"`
Author string `yaml:"author"`
Tags []string `yaml:"tags"`
Description string `yaml:"description"`
SimilarPosts []string `yaml:"similar_posts"`
}
type Content []byte
type MarkdownPost struct {
RawContent []byte // frontmatter + separators + content
Path string
Frontmatter Frontmatter // frontmatter
Content Content // does not include frontmatter
Embedding []float64
}Once a markdown file is read, I do a few operations on it. First, I strip the hugo shortcodes. Then I render the markdown document to HTML by using the blackfriday markdown processor. Afterwards, I strip out the HTML tags. This leaves me with a plain text, which is ready to be passed into the model for embedding calculation. I did this because I worried that the raw contents of the file with shortcodes might yield results that are not representative. If that’s true or not - I do not know.
Now I need to calculate the embeddings. This is done in a following pass through, where I iterate over all the posts and fetch their embeddings from the api.
The third and final pass over the posts calculates the cosine similarity between each of the posts. It then takes the top 3 most similar posts, and marks their paths in the frontmatter struct’s similar posts property. The markdown documents are then saved.
This is all quite inefficient and I could optimize this, but I’m really not worried about the performance here.
There are also a few caveats - first, there’s a script that updates the markdown files that I’m working on. I’m not very fond of this, as it could lead to loss of data. If I were to run the script and while it’s executing change something, the change would get overwritten by the script once its job is complete. However, since I’m the only person working on this blog, and I have it version controlled I deem this an acceptable risk. I’ve had to do it this way as I could not figure out an alternative to hook into the hugo’s build chain.
If you’d like a deeper look at the code - the full code for the CLI is available here.
The Hugo template
With all my posts now containing a similar_posts property in their frontmatter, all that’s left to do is to adjust the template I use to render the related posts section. The template will render the similar_posts property if it’s present. If it’s not, it will fall back to the Hugo’s built-in related feature.
Here’s what it looks like:
{{ $similarPosts := .Params.similar_posts }}
{{ if and (isset .Params "similar_posts") (gt (len $similarPosts) 0) }}
<h4>Related posts</h4>
<ul>
{{ range $index, $simpost := $similarPosts }}
{{ with $.Site.GetPage $simpost }}
<li><a href="{{ .RelPermalink }}">{{ .LinkTitle }}</a></li>
{{ end }}
{{ end }}
</ul>
{{ else }}
{{ $related := .Site.RegularPages.Related . | first 3 }}
{{ if gt (len $related) 0 }}
<h4>Related posts</h4>
<ul>
{{ range $related }}
<li><a href="{{ .RelPermalink }}">{{ .LinkTitle }}</a></li>
{{ end }}
</ul>
{{ end }}
{{ end }}
With this, the blog is armed to provide ML related posts instead of relying on keywords and tags.
The results
Let’s take my previous post - Probabilistic Early Expiration in Go - and compare the tag based related posts vs the ML related posts.
The old:
The new:
- Speeding hexo (or any page) for PageSpeed insights
- Kestrel vs Gin vs Iris vs Express vs Fasthttp on EC2 nano
- Go’s defer statement
For this particular case, I feel like the tag based recommendations are semantically closer to what I would expect. Nevertheless, I’m planning on sticking with the ML generated ones at least for a short while to get to know them better!
So, is it all worth it? Well, probably not. I wasn’t really doing this for any sort of tangible result. I don’t even have the metrics to verify that this indeed has any effect. However, this was a fun little experiment and a good entry to getting to know ML a little. I’ll probably do more and deeper dives into ML at some point and maybe re-visit this feature for a second iteration in the future.
Thanks for reading! If you’ve got any comments or suggestions, do leave a comment below.